FIRST NEURAL ARCHITECTURE
Content:
· Why are layers added?
· Receptive Field
· The Convolutional Mathematics
· MaxPooling
o Max-Pooling Invariances
· Layer Counting
· Kernels in Layer 1
· is 3x3 misleading?
· Multi-Channel Convolution
· Our Network NOW
· Assignment
Understanding of basics

Here we are “reading” 3x3 numbers on a 5x5 image. The moment we read these 3x3 pixels we multiply them by some 3x3 other numbers (identified by a DNN). These “other 3x3 numbers” are called Kernels.
Reference: Upload the image to see the details.
So, there exist simple 3x3 matrix numbers that can easily identify basic lines/edges.
So if we convolve a 3x3 kernel on a 5x5 image, the output we would create will have a resolution of 3x3. This is true only when:
1. we are not going outside of the image (by adding imaginary numbers). This by the way is called padding. We can add imaginary black/white (0/1/255) numbers and then allow our kernel to slide out of the image.
2. we are not using a stride of more than 1, i.e., we will cover each 3x3 section immediately after 1 pixel
In the images above, our kernel skips/jumps only 1 pixel. If we were to jump/skip 2 pixels, then our kernel has a stride of 2 (pixels).
Why are layers added?
Convolutional neural networks (CNNs) are designed to process data with a grid-like topology, such as an image. They consist of multiple layers of interconnected nodes, each of which performs a specific function on the input data.
Layers are added to a CNN for a variety of reasons, including:
1. To extract features from the input data: The first layer of a CNN is often a convolutional layer, which applies a set of filters (Kernels) to the input data and produces a set of feature maps. These feature maps are then passed through a series of additional layers, which extract and refine the features further.
2. To increase the non-linearity of the model: CNNs can be very effective at learning complex relationships in the data, but this requires that the model be able to capture non-linear patterns. By adding layers to the model, it becomes more expressive and is better able to capture these non-linear patterns.
3. To improve the model’s ability to generalize: As the model becomes deeper and more complex, it is able to learn more abstract features of the data, which can improve its ability to generalize to new, unseen data.
4. To reduce overfitting: By adding layers to the model, it becomes more expressive and is able to capture more fine-grained details in the data. However, this can also lead to overfitting, where the model performs well on the training data but poorly on test data. To mitigate this, it is often necessary to use techniques such as dropout or weight decay to regularize the model and prevent overfitting.
What Else You Should Thing: 🤔 😕
If we could identify the components of the object, we could easily achieve our objective — say, let’s detecting an object (car). Some patterns, which in turn can be constructed from textures, can be used to build certain parts of the objects (Engine). Edges and gradients are necessary to create every texture.


To achieve this mechanically, we create layers. Our initial layers should be able to extract basic features like edges and gradients, as expected. Then, slightly sophisticated characteristics like textures and patterns would be built in the next layers. Subsequently layers might then construct object pieces that could later be assembled into whole objects. The picture up above shows this.
As we gradually add layers, the network’s receptive field expands. Each pixel in the second layers has only “seen” (had a receptive field for) 3x3 pixels if we are using 3x3 kernels. The entire image must first be processed by the network prior to any decision being made. To do this, we build layers. Also take into account the fact that in a 400x400 image, all necessary or significant edges and gradients can be generated or observed inside 11x11 pixels. However, if we were viewing a face, the various parts would occupy a lot more space (or the number of pixels).
RECEPTIVE FIELD

The receptive field of a neuron in a convolutional neural network (CNN) is the region of the input image that the neuron is able to “see” or “receive” information from. The size and shape of the receptive field can have a significant impact on the ability of the CNN to recognize patterns in the input data.
In a CNN, the receptive field is a function of size and stride of the filters used, the size of the pooling kernels used in the pooling layers. As the receptive field increases, the neuron is able to see more of the input image, which can allow it to recognize more complex patterns.
Receptive field is an important concept in CNNs because it determines the ability of the network to recognize patterns in the input data. By carefully designing the receptive fields of the neurons in a CNN, it is possible to achieve good performance on a variety of tasks, such as image classification and object recognition.

Here, a 5x5 image represents our initial layer. The output resolution will be a channel with 3x3 pixels/values because we are convolving this 5x5 image with a kernel that is 3x3 in size. We will only receive 1 output when we convolve on this 3x3 channel with a 3x3 kernel. Here, we’ve added two levels.
We could have used a 5x5 kernel directly to produce an output of 1 or 1x1. As a result, running a 3x3 kernel twice is the same as running a 5x5 kernel. This also implies that a receptive field of 5x5 is produced by two layers of 3x3 in size.
The final global receptive field, at the final prediction layer or output layer, should be the same size as the image, as we have discussed in previous blog. This is crucial because the network must “see” the entire image before it can accurately forecast what the image is about.
This would imply that in order to achieve a final receptive field that is the same size as the object, we must add as many layers as necessary. Our final receptive field will be the size of the image because we have chosen to consider the size of the object to be equal to the size of the image. (We are aware that this is untrue; photos can contain objects of any size, but we must take this limitation into account while developing our conceptions. We would later work on the necessary steps to lift this restriction.)
Math Behind Convolution 😊
Don’t worry About the Math. It will Come naturally and We have Machines to do this. Just understand the concept.


As seen in the figure above, whenever our kernel stops on a 3x3 area, we are seeing 9 multiplications and the sum of those 9 multiplications being sent to the output channel.
The numbers in the output channel represent the “confidence” in locating a specific feature.
Higher values indicate greater confidence, while lower (or more negative) values indicate greater “confidence” in the absence of the trait.
The following are some instances of edge detectors:

Let’s Codify it and understand.

Let’s examine this in terms of some numbers. Let’s examine what an image of a vertical edge would resemble:
0.2 0.2 0.9 0.2 0.5
0.1 0.1 0.9 0.3 0.2
0.0 0.2 0.8 0.1 0.1
0.2 0.3 0.9 0.1 0.2
0.1 0.1 0.9 0.3 0.2
The values shown in bold represents a vertical line in this image
Let us define our vertical kernel as:
-1 2 -1
-1 2 -1
-1 2 -1
After convolving the values, we get:
-2.0 4.3 -2.3
-1.7 4.1 -2.1
-1.7 4.1 -2.1
We can clearly see in this example that the central vertical values in the 3x3 output layer above, the detection of the vertical line. Not only we have detected the vertical line, we are also passing on an image/channel which shows a vertical line.
We can clearly see in this example that the central vertical values in the 3x3 output layer above, the detection of the vertical line. Not only we have detected the vertical line, we are also passing on an image/channel which shows a vertical line.
Spend a few moments to think about this bold line.
How many layers would we need to move from 400x400 image to 1x1?
As we saw in the last blog, we need to add about 200 layers (because we lower the size of the image or channel by 2 with each layer, 400/2 = 200) to complete the process.
These have a ridiculously high number of layers. Better solutions exist than this
MAXPOOLING
Max pooling is a technique used in convolutional neural networks (CNNs) to reduce the size of the input feature maps by taking the maximum value of a certain window size over the feature map.
This is done by applying a max filter to the feature map and sliding it over the entire feature map, taking the maximum value of each region that the filter covers and creating a new feature map with these maximum values.

The main purpose of max pooling is to down-sample the feature maps, which helps to reduce the computational cost of processing the data and also helps to reduce overfitting by providing some translation invariance.
Translation invariance refers to the property of a model to produce the same output when the input is translated (moved) in space. In the context of CNNs, translation invariance means that the model should produce the same output when the input image is translated, as long as the object of interest is still present in the image. This is useful because it allows the model to recognize an object regardless of its position in the input image.
For example, consider a CNN that is trained to recognize faces in images. If the model has translation invariance, then it should be able to recognize a face whether it appears at the top-left, bottom-right, or any other position in the image. This is because the features that are important for recognizing a face, such as the eyes, nose, and mouth, are likely to be present no matter where the face appears in the image.
Max pooling is one technique that can be used to introduce translation invariance into a CNN. By down-sampling the input feature maps using max pooling, the model is able to recognize features at different positions in the input image and still produce the same output. This can be useful for tasks such as object recognition, where the position of the object in the image is not always predictable.
LAYER COUNT
400 | 398 | 396 | 394 | 392 | 390 | MP (2x2)
195 | 193 | 191 | 189 | 187 | 185 | MP (2x2)
92 | 90 | 88 | 86 | 84 | 82 | MP (2x2)
41 | 39 | 37 | 35 | 33 | 31 | MP (2x2)
15 | 13 | 11| 9 | 7 | 5 | 3 | 1
By using MaxPooling we have reduced the layer count from 200 to 27. That’s much better.
@Layer 1, The Situation of a Kernel
We would need a set of edges and gradients to be detected to be able to represent the whole image. Through experiments, we have learned that we should use around 32 or 64 kernels in the first layer, increasing the number of kernels slowly. Let us assume we add 32 kernels in the first layer, 64 in second, 128 in third, and so on.
How to Interpret 3X3
The number of channels in our kernels must match the number in the input channel. Our kernel will have 32 channels because the second layer’s input has 32 channels. The kernel’s channels (such as channel #23) will only scan one channel at a time (channel number 23 in the input).
Let’s Apply All learnings and see how convolution works.
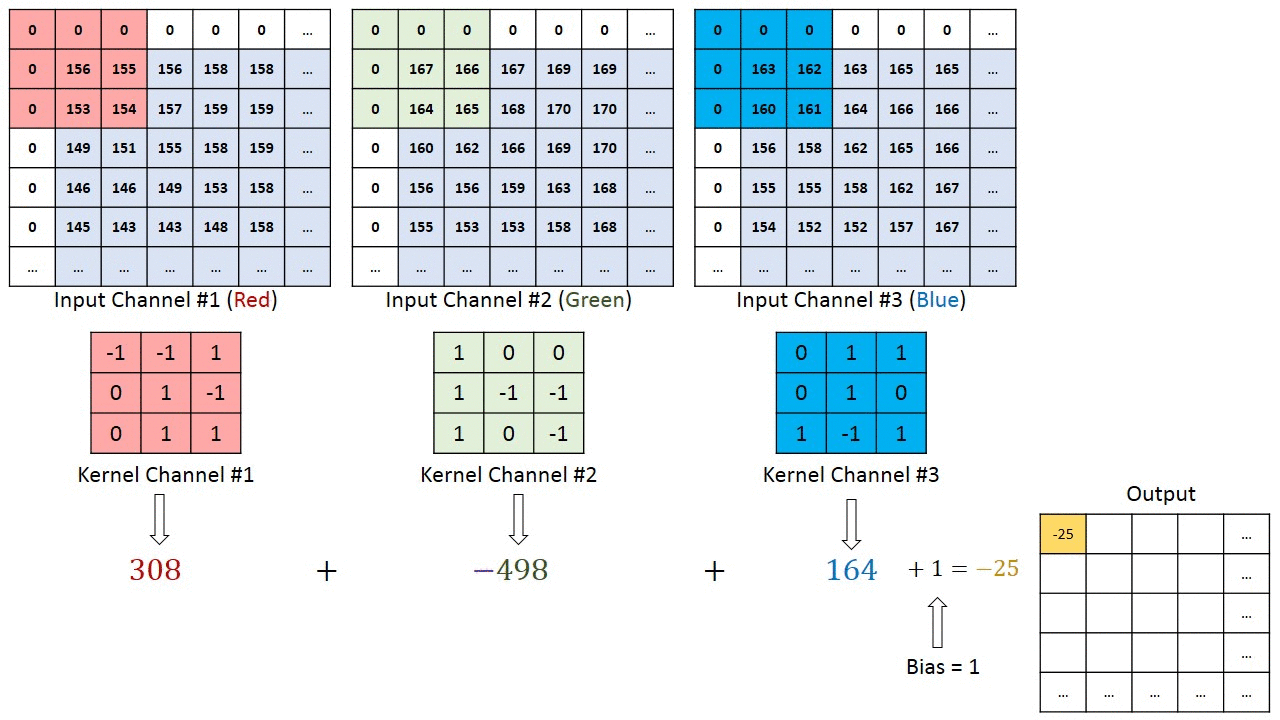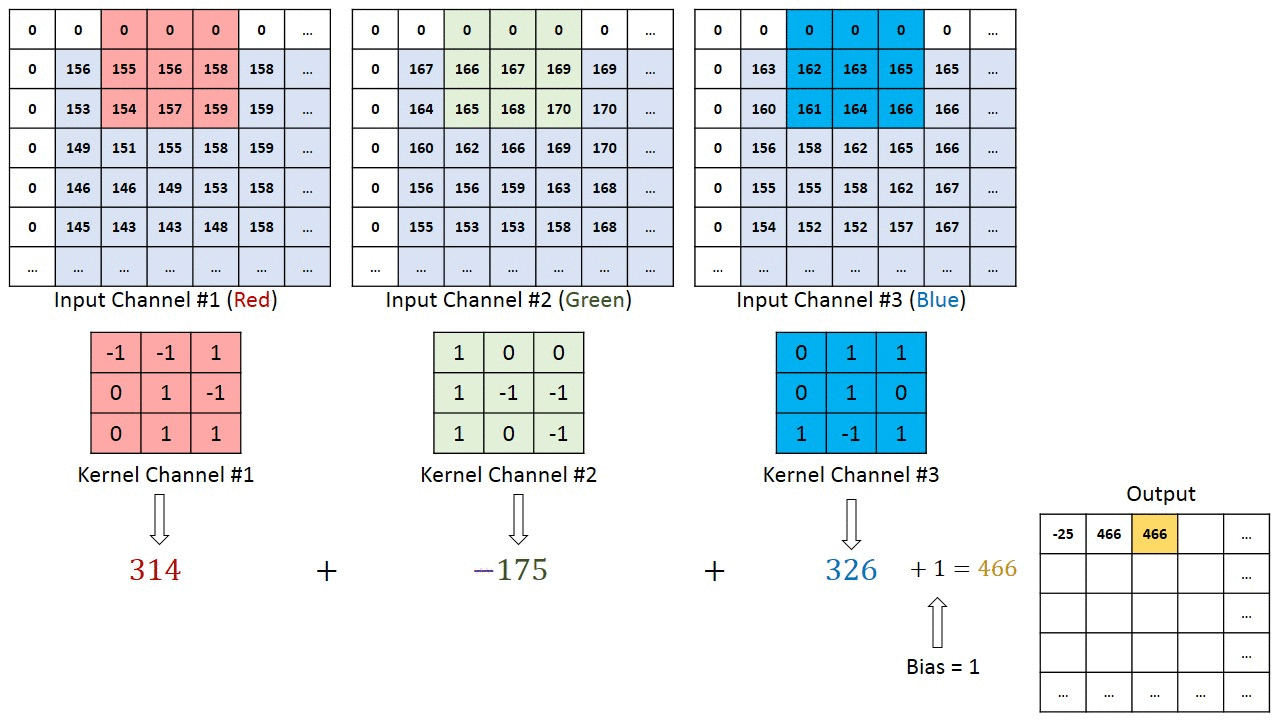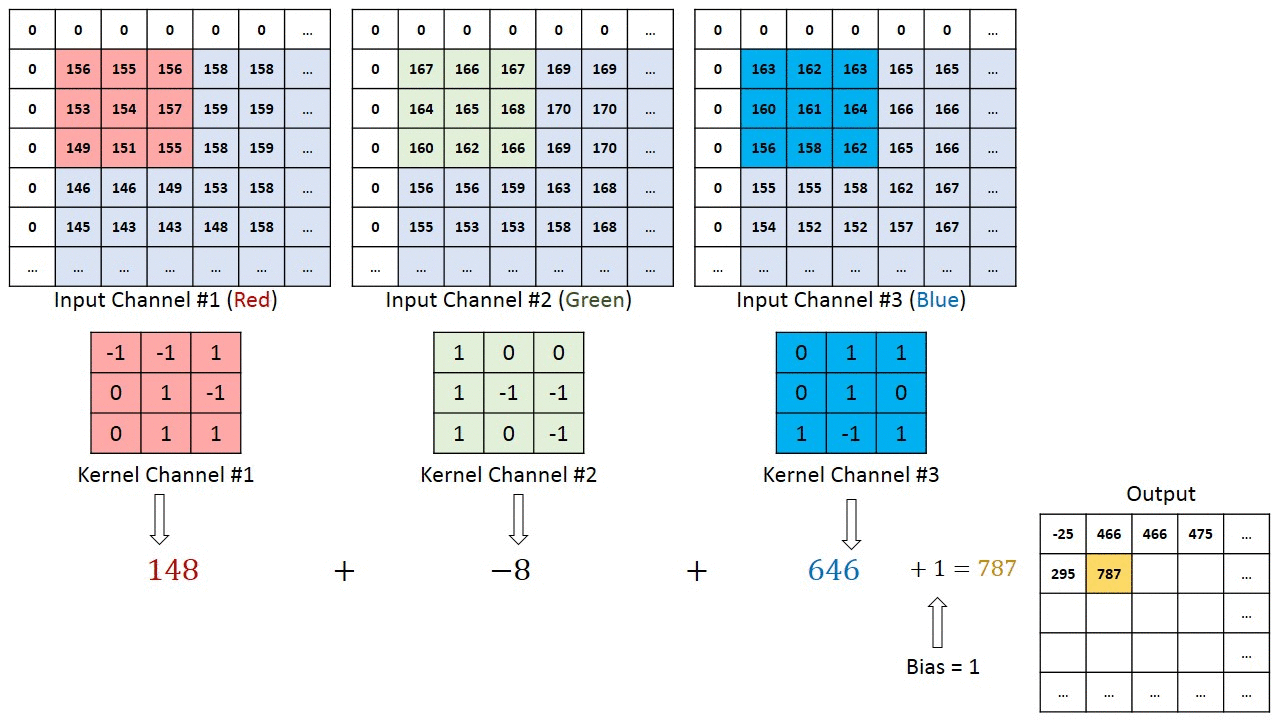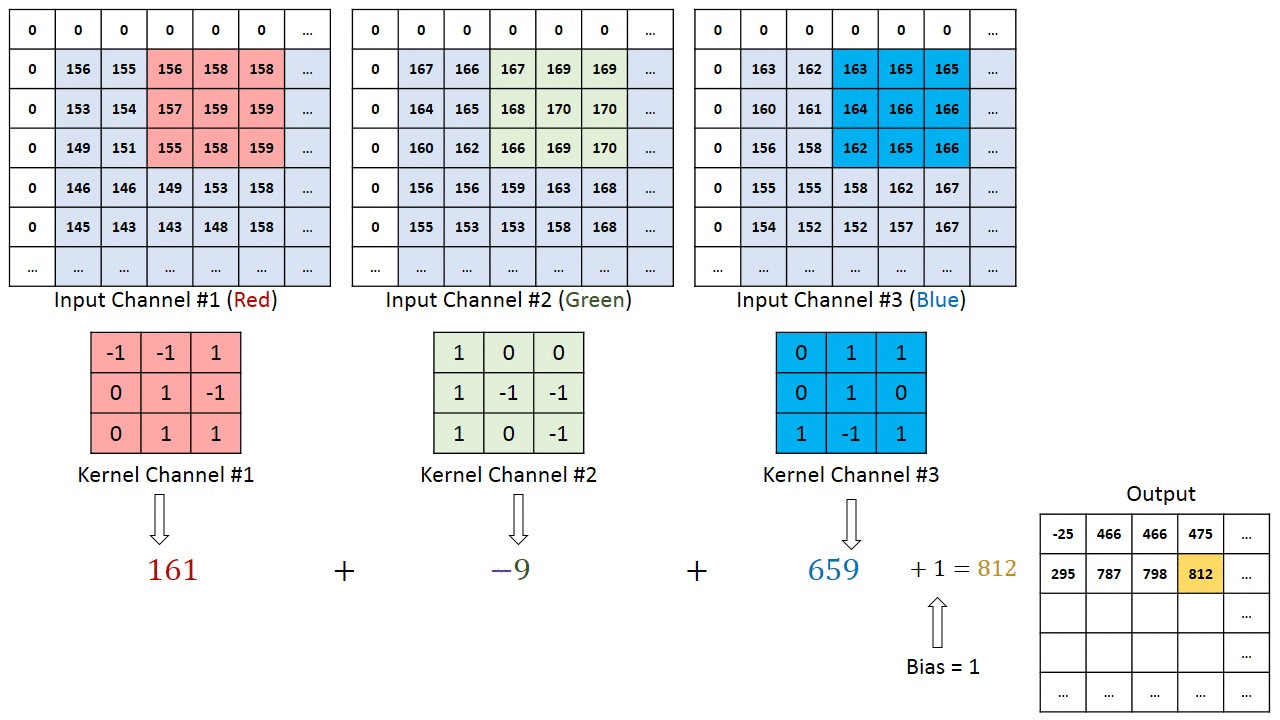
We are adding an increasing number of kernels as generally required:
400x400x1 | (3x3)x32 | 398x398x32
398x398x32 | (3x3)x64 | 396x396x64
396x396x64 | (3x3)x128 | 394x394x128
394x394x128 | (3x3)x256 | 392x392x256
392x392x256 | (3x3)x512 | 390x390x512
MaxPooling
195x195x512…
There is an issue here. Even though we have only used a tiny number of kernels up to this point — 32+64+128+256+512 — we currently have 992 pictures in our memory. MaxPooling helped us overcome the problem of high channel sizes, but we still need to find a solution to minimise the number of channels without negating the goal of increasing the number of channels (something we desperately want).
We will Do the Magic in next blog (Hint: We have 1x1 Kernel)
